Turn anything into LLM-Ready Data: A Guide for every file type
Welcome, reader! Today, I'm writing about a topic that you'll need at some stage of building any AI-powered application: transforming all kinds of files — PDFs, MP3s, MP4s, and even URLs — into data that you can feed directly into your LLMs.
The logic behind this post?
- show you how to prepare your data for LLM consumption without losing time on guesswork.
What You Need To Know
The core idea: Streamlined Data Processing
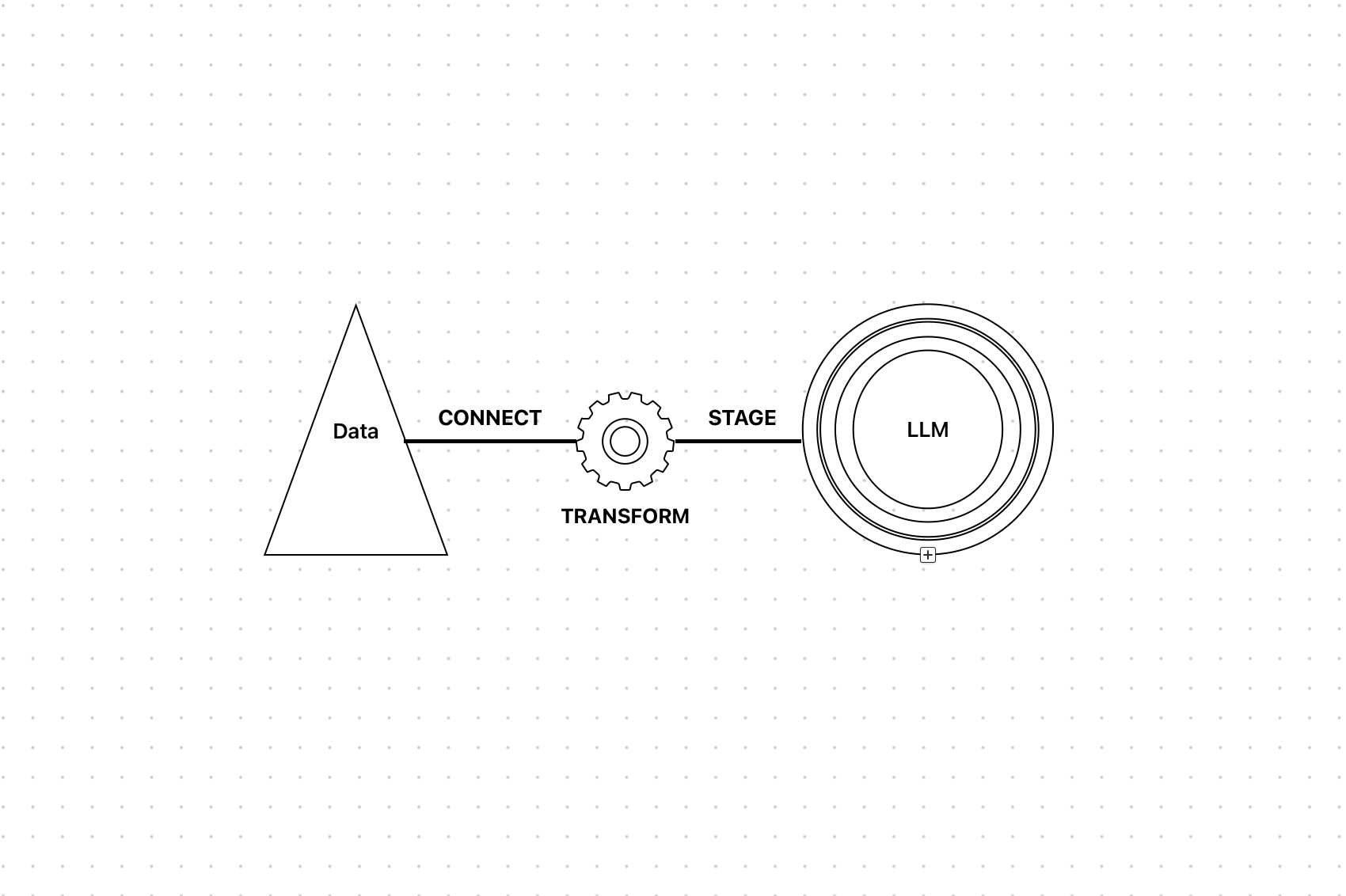
Before we begin with the code, here's the big picture:
- User Input → Could be a file (PDF, MP3, MP4) or just a URL.
- Pre-Processing → Using specialized tools to extract text and structure.
- Storage → Saving the structured data somewhere (e.g., Supabase).
- Feed to LLM → Now your AI model can analyze, answer queries, or do anything you want with that data.
we'll start with text-based files like PDF and DOCXs (& more text formats), then move to audio(MP3), video (MP4), and finally URLs
Parsing files with Unstructured
Unstructured is an open-source library that transforms complex, unstructured data from raw data sources into clean, structured data that can be used in GenAI applications.
Step 1: Set up Unstructured
- Sign up here
- Get your API key and API URL from your Account Settings.
Step 2: Install Unstructured CLI package
pip install unstructured-ingest
Step 3: Set the following environment variables:
- Set
UNSTRUCTURED_API_KEYto your API key. - Set
UNSTRUCTURED_API_URLto your API URL.
To extract and process data, you need two directories: an input directory and an output directory. The input directory holds the files you want to extract, while the output directory stores the processed data.
Step 4: Let's do the parsing
- Configure the Input Directory:
- Identify the source path(path of the folder that consists of the files that need to be extracted) on your local machine.
- Specify this path to set up the input directory.
- Configure the Output Directory:
- Determine the destination path where you want the processed data to be saved.
- Specify this path to set up the output directory.
- Set Up the Unstructured Pipeline:
- Use the provided code to configure the pipeline.
Pipeline.from_configs( context=ProcessorConfig( disable_parallelism=True, num_processes=1, ), indexer_config=LocalIndexerConfig(input_path=input_dir), downloader_config=LocalDownloaderConfig(), source_connection_config=LocalConnectionConfig(), partitioner_config=PartitionerConfig( partition_by_api=True, api_key=api_key, partition_endpoint=api_url, strategy="auto", additional_partition_args={ "split_pdf_page": True, "split_pdf_allow_failed": True, "split_pdf_concurrency_level": 1, }, ), uploader_config=LocalUploaderConfig(output_dir=output_dir), ).run()
- Process and Write Results:
- The pipeline will read the files from the input directory.
- It will then process these files and write the results to the output directory.
How It Works
partition_by_api=True: This tells Unstructured to use its hosted API for parsing files instead of processing them locally. This is particularly useful for reducing local resource usage.strategy="auto": Automatically selects the best approach for parsing based on the file type, ensuring optimal performance.
Once the pipeline runs, your parsed and structured data will be stored in the output directory.
Optional Configuration_:
If needed, you can add chunking configuration to split the document into appropriately-sized chunks for use cases such as Retrieval Augmented Generation (RAG). For today, we're focusing on extracting text from files.
Moving to Production
While the input-output directory structure works well for testing and small-scale use cases, it isn't ideal for production. To integrate this process into real-world applications, we need to use source connectors and destination connectors. Unstructured supports many source connectors and destination connectors, but unfortunately supabase isn't a part of it. However, since Supabase is not natively supported by Unstructured, here's how you can set it up:
Step 1: Handle File Uploads
When a user uploads files through your Next.js frontend (or any other frontend), follow these steps:
- Temporarily store the uploaded files in a temp input folder on your server.
- This folder will act as a staging area for files that need to be processed.
- At the same time, create a temp output folder where the processed data will be stored after running through the pipeline.
Step 2: Process Files with the Pipeline
Once the files are stored in the temp input folder:
- Pass the path of the temp input folder and temp output folder to the Unstructured pipeline for processing.
After the pipeline finishes processing:
- Delete the temp input folder to free up storage space on your server.
- The pipeline will automatically save the processed data in the temp output folder.
Step 3: Store Processed Data in Supabase
After the pipeline has stored the processed data in the temp output folder:
- Loop through the files in the temp output folder.
For each file:
- Upload the processed data(extracted text) to Supabase storage for long-term storage and easy access.
- Once all files are uploaded to Supabase:
- Delete the temp output folder to keep your server clean and efficient.
Final Workflow Overview
Here's how the entire process flows:
- User uploads files → Save them in a temp input folder.
- Run the pipeline → Process the files and store the results in a temp output folder.
- Upload to Supabase → Move processed data to Supabase storage.
- Cleanup → Delete both the temp input and output folders.
Handling MP3 files with Lumos
"Audio can be a goldmine for LLMs, but only if you can transcribe it effectively." — me
Introducing Lumos — a small but handy library that we built to simplify audio transcription allowing you to focus on AI features rather than being stuck with transcription services
Let's extract text from mp3 files.
Lumos Documentation
_Documentation for Lumos - Common utils across lumira labs_lumiralabs.github.io
Step 1: Install Lumos
To start using Lumos, install it via pip:
uv pip install git+https://github.com/lumiralabs/lumos
Step 2: Transcribe MP3 Files in Python
Here's how you can transcribe an MP3 file with Lumos:
The transcribe method accepts audio bytes. Instead of opening the file, you can pass audio bytes to the transcribe method. This way, you can transcribe audio without having to read the file.
This way:
from lumos "text-purple-400">import lumos # Open the audio file in binary mode with open("audio_file.mp3", "rb") as audio_file: # Pass the file to Lumos "text-purple-400">for transcription transcription = lumos.transcribe(audio_file) # Print the transcribed text print(transcription.text)
How It Works
lumos.transcribe(audio_file): This function reads the binary content of the audio file and returns the transcribed text.- Powered by LiteLLM: Lumos leverages LiteLLM behind the scenes to handle the heavy lifting, so you don't need to do any additional setup.
Tips for Larger Files
If you're working with longer audio files, consider these:
- Chunk the Audio: Break larger files into smaller segments before transcription. This reduces processing time and makes handling errors easier.
- Use Asynchronous Processing: For apps handling multiple files, integrate asynchronous task managers like Celery or Redis Queue (RQ) to process files in the background.
Handling MP4 Files: Extract, Then Transcribe
"Video is just audio with pictures attached." — me again.
To process MP4 files, we'll first extract the audio as an MP3 file and then transcribe it into text.
Step 1: Extract Audio with yt-dlp
We'll use yt-dlp, a command-line program, to extract audio from video files and convert it to MP3 format. It uses FFmpeg for audio conversion (FFmpeg is a powerful open-source tool for processing audio, video, and other multimedia files, allowing conversion, editing, and streaming). The implementation is shown in the independent python function below.
Step 2: Transcribe audio with Lumos
Once the audio has been extracted, you can transcribe it using Lumos, just like we did for MP3 files earlier.
from lumos "text-purple-400">import lumos # Open the extracted audio file in binary mode with open("output_filename.mp3", "rb") as audio_file: transcription = lumos.transcribe(audio_file) # Print the transcribed text print(transcription.text)
Independent Python Function for Video Processing
Here's a complete standalone function for extracting audio from a video and transcribing it
"text-purple-400">import os "text-purple-400">import tempfile from lumos "text-purple-400">import lumos "text-purple-400">import yt_dlp "text-purple-400">async def process_video_file(file_path: str) -> str: """ Extract audio from a video file and transcribe it into text. Args: file_path (str): Path to the video file. Returns: str: Transcribed text from the video's audio. """ "text-purple-400">try: print(f"Processing video: {file_path}") with tempfile.TemporaryDirectory() as temp_dir: # Define the path "text-purple-400">for the extracted audio file audio_path = os.path.join(temp_dir, "audio.mp3") # Configure yt-dlp to extract audio ydl_opts = { "format": "bestaudio/best", "postprocessors": [ { "key": "FFmpegExtractAudio", "preferredcodec": "mp3", "preferredquality": "192", } ], "outtmpl": audio_path, "quiet": True, "no_warnings": True, } # Extract audio using yt-dlp with yt_dlp.YoutubeDL(ydl_opts) as ydl: ydl.download([f"file://{file_path}"]) # Open the extracted audio file and transcribe it with open(audio_path, "rb") as audio_file: transcription = lumos.transcribe(audio_file) print(f"Transcription completed: {transcription.text[:100]}...") "text-purple-400">return transcription.text except Exception as e: print(f"Error processing video file {file_path}: {str(e)}") raise ValueError(f"Video processing failed: {str(e)}")
How This Function Works
- Temporary Directory: Creates a temporary folder to store the extracted audio file.
- Audio Extraction: Configures yt-dlp to extract the audio track and convert it to MP3 using FFmpeg.
- Transcription: Uses Lumos to transcribe the MP3 file into text.
Final Workflow for Videos
- Input: Provide a video file (MP4).
- Extract Audio: Use yt-dlp to convert the video into an MP3.
- Transcribe Audio: Use Lumos to turn the MP3 into text.
- Output: Receive the transcribed text, ready for LLM processing.
Processing URLs with Firecrawl
"Turn any website into LLM-ready Markdown."
Firecrawl is a tool that converts websites into clean, structured formats that are ready for LLMs to process.
Step 1: Install Firecrawl
pip install firecrawl-py
Step 2: Scrape a URL
Now, let's extract data from a webpage. Use the following Python code:
from firecrawl "text-purple-400">import FirecrawlApp # Initialize Firecrawl with your API key app = FirecrawlApp(api_key="fc-YOUR_API_KEY") # Scrape the webpage and get the result scrape_result = app.scrape_url( "https://www.firecrawl.dev", params={"formats": ["markdown"]} # Request the output in markdown format ) # Print the extracted data print(scrape_result)
Key Outputs
When you scrape a URL with Firecrawl, you'll get three main types of output:
- Markdown: A clean, easy-to-read text version of the webpage.
- HTML: The original HTML content of the webpage.
- Metadata: Details about the page, such as the title, description, language, and more.
Putting It All Together
Larger workflow of creating LLM-ready data:
- Input: The user submits a URL, uploads a file, or provides audio/video content.
- Identify the Type: Automatically determine the type of data — whether it's a URL, PDF, MP3, or MP4.
Process the Data:
- Use Unstructured to parse and process text-based files.
- Use Lumos + yt-dlp to handle audio and video files.
- Use Firecrawl to scrape and clean URLs.
- Store the Output: Save the structured data in a database like Supabase, making it accessible for future use.
- Cleanup: Delete any temporary files or folders created during processing to free up server resources.
- Feed to the LLM: Use the cleaned data for various applications, such as answering questions, summarizing content, or powering chatbot responses.